Раздел 1. Теория вероятностей
Раздел 2. Математическая статистика
Лекция 10. Сущность выборочного метода. Числовые характеристики выборки
1. Задачи и методы математической статистики
Математическая статистика - это раздел математики, посвященный методам сбора, анализа и обработки результатов статистических данных наблюдений для научных и практических целей.
Пусть требуется изучить совокупность однородных объектов относительно некоторого качественного или количественного признака, характеризующего эти объекты. Например, если имеется партия деталей, то качественным признаком может служить стандартность детали, а количественным - контролируемый размер детали.
Иногда проводят сплошное исследование, т.е. обследуют каждый объект относительно нужного признака. На практике сплошное обследование применяется редко. Например, если совокупность содержит очень большое число объектов, то провести сплошное обследование физически невозможно. Если обследование объекта связано с его уничтожением или требует больших материальных затрат, то проводить сплошное обследование не имеет смысла. В таких случаях случайно отбирают из всей совокупности ограниченное число объектов (выборочную совокупность) и подвергают их изучению.
Основная задача математической статистики заключается в исследовании всей совокупности по выборочным данным в зависимости от поставленной цели, т.е. изучение вероятностных свойств совокупности: закона распределения, числовых характеристик и т.д. для принятия управленческих решений в условиях неопределенности.
2. Виды выборок
Генеральная совокупность – это совокупность объектов, из которой производится выборка.
Выборочная совокупность (выборка) – это совокупность случайно отобранных объектов.
Объем совокупности – это число объектов этой совокупности. Объем генеральной совокупности обозначается N, выборочной – n.
Пример:
Если из 1000 деталей отобрано для обследования 100 деталей, то объем генеральной совокупности N = 1000, а объем выборки n = 100.
При составлении выборки можно поступить двумя способами: после того, как объект отобран и над ним произведено наблюдение, он может быть возвращен либо не возвращен в генеральную совокупность. Т.о. выборки делятся на повторные и бесповторные.
На практике обычно пользуются бесповторным случайным отбором.
Для того, чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли. Выборка должна правильно представлять пропорции генеральной совокупности. Выборка должна быть репрезентативной (представительной).
В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если ее осуществлять случайно.
Если объем генеральной совокупности достаточно велик, а выборка составляет лишь незначительную часть этой совокупности, то различие между повторной и бесповторной выборками стирается; в предельном случае, когда рассматривается бесконечная генеральная совокупность, а выборка имеет конечный объем, это различие исчезает.
Пример:
В американском журнале «Литературное обозрение» с помощью статистических методов было проведено исследование прогнозов относительно исхода предстоящих выборов президента США в 1936 году. Претендентами на этот пост были Ф.Д. Рузвельт и А. М. Ландон. В качестве источника для генеральной совокупности исследуемых американцев были взяты справочники телефонных абонентов. Из них случайным образом были выбраны 4 миллиона адресов, по которым редакция журнала разослала открытки с просьбой высказать свое отношение к кандидатам на пост президента. Обработав результаты опроса, журнал опубликовал социологический прогноз о том, что на предстоящих выборах с большим перевесом победит Ландон. И ... ошибся: победу одержал Рузвельт. Этот пример можно рассматривать, как пример нерепрезентативной выборки. Дело в том, что в США в первой половине двадцатого века телефоны имела лишь зажиточная часть населения, которые поддерживали взгляды Ландона.
3. Способы отбора
На практике применяются различные способы отбора, которые можно разделить на 2 вида:
- Отбор не требует расчленения генеральной совокупности на части а) простой случайный бесповторный; б) простой случайный повторный.
- Отбор, при котором генеральная совокупность разбивается на части. а) типичный отбор; б) механический отбор; в) серийный отбор.
Простым случайным называют такой отбор, при котором объекты извлекаются по одному из всей генеральной совокупности (случайно).
Типичным называют отбор, при котором объекты отбираются не из всей генеральной совокупности, а из каждой ее «типичной» части. Например, если деталь изготавливают на нескольких станках, то отбор производят не из всей совокупности деталей, произведенных всеми станками, а из продукции каждого станка в отдельности. Таким отбором пользуются тогда, когда обследуемый признак заметно колеблется в различных «типичных» частях генеральной совокупности.
Механическим называют отбор, при котором генеральную совокупность «механически» делят на столько групп, сколько объектов должно войти в выборку, а из каждой группы отбирают один объект. Например, если нужно отобрать 20% изготовленных станком деталей, то отбирают каждую 5-ую деталь; если требуется отобрать 5% деталей- каждую 20-ую и т.д. Иногда такой отбор может не обеспечивать репрезентативность выборки (если отбирают каждый 20-ый обтачиваемый валик, причем сразу же после отбора производится замена резца, то отобранными окажутся все валики, обточенные затупленными резцами).
Серийным называют отбор, при котором объекты отбирают из генеральной совокупности не по одному, а «сериями», которые подвергают сплошному обследованию. Например, если изделия изготавливаются большой группой станков-автоматов, то подвергают сплошному обследованию продукцию только нескольких станков.
На практике часто применяют комбинированный отбор, при котором сочетаются указанные выше способы.
4. Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка, причем значение – наблюдалось раз, - раз, ... - раз. – объем выборки.
Наблюдаемые значения называются вариантами, а последовательность вариант, записанных в возрастающем порядке – вариационным рядом.
Числа наблюдений называются частотами (абсолютными частотами), а их отношения к объему выборки – относительными частотами или статистическими вероятностями.
Если количество вариант велико или выборка производится из непрерывной генеральной совокупности, то вариационный ряд составляется не по отдельным точечным значениям, а по интервалам значений генеральной совокупности. Такой вариационный ряд называется интервальным. Длины интервалов при этом должны быть равны.
Статистическим распределением выборки называется перечень вариант и соответствующих им частот или относительных частот.
Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (суммы частот, попавших в этот интервал значений).
Точечный вариационный ряд частот может быть представлен таблицей:
| ... | ||||
|---|---|---|---|---|
| ... |
Аналогично можно представить точечный вариационный ряд относительных частот.
Задача 1.
Число букв, соответствующих гласным звукам, в некотором тексте Х оказалось равным 1000. Первой встретилась буква «я», второй – буква «и», третьей – буква «а», четвертой – «ю». Затем шли буквы «о», «е», «у», «э», «ы».
Выпишем места, которые они занимают в алфавите, соответственно имеем: 33, 10, 1, 32, 16, 6, 21, 31, 29.
После упорядочения этих чисел по возрастанию получаем вариационный ряд: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Частоты появления букв в тексте: «а» – 75, «е» –87, «и» – 75, «о» – 110, «у» – 25, «ы» – 8, «э» – 3, «ю» – 7, «я» – 22.
Составим точечный вариационный ряд частот:
| 1 | 6 | 10 | 16 | 21 | 29 | 31 | 32 | 33 | |
|---|---|---|---|---|---|---|---|---|---|
| 75 | 87 | 75 | 110 | 25 | 18 | 3 | 7 | 22 |
Задача 2.
Задано распределение частот выборки объема n = 20.
Составьте точечный вариационный ряд относительных частот.
| 2 | 6 | 12 | |
|---|---|---|---|
| 3 | 10 | 7 |
Решение.
Найдем относительные частоты:
| 2 | 6 | 12 | |
|---|---|---|---|
| 0,15 | 0,5 | 0,35 |
При построении интервального распределения существуют правила выбора числа интервалов или величины каждого интервала. Критерием здесь служит оптимальное соотношение: при увеличении числа интервалов улучшается репрезентативность, но увеличивается объем данных и время на их обработку. Разность между наибольшим и наименьшим значениями вариант называют размахом выборки.
Для подсчета числа интервалов обычно применяют эмпирическую формулу Стреджесса (подразумевая округление до ближайшего удобного целого): .
Соответственно, величину каждого интервала h можно вычислить по формуле:
Эмпирическая функция распределения
Рассмотрим некоторую выборку из генеральной совокупности. Пусть известно статистическое распределение частот количественного признака Х. Введем обозначения: – число наблюдений, при которых наблюдалось значение признака, меньшее ; – общее число наблюдений (объем выборки). Относительная частота события Х < х равна . Если х изменяется, то изменяется и относительная частота, т.е. относительная частота - есть функция от . Т.к. она находится эмпирическим (опытным) путем, то она называется эмпирической.
Эмпирической функцией распределения (функцией распределения выборки) называют функцию, определяющую для каждого х относительную частоту события Х < х.
Различие между эмпирической и теоретической функциями распределения состоит в том, что теоретическая функция определяет вероятность события Х < x, а эмпирическая функция - относительную частоту этого же события. Для составления эмпирической функции распределения берется не вся генеральная совокупность, а выборка, и вероятность заменяется относительной частотой . При большом n и мало отличаются друг от друга.
Т.о. целесообразно использовать эмпирическую функцию распределения выборки для приближенного представления теоретической (интегральной) функции распределения генеральной совокупности.
обладает всеми свойствами .
- Значения принадлежат интервалу [0; 1].
- - неубывающая функция.
- Если – наименьшая варианта, то , при ; если – наибольшая варианта, то , при .
Т.е. служит для оценки .
График эмпирической функции называется кумулятой.
Кумулята имеет такой же вид, как и график теоретической функции распределения.
Если задан интервальный вариационный ряд, то для составления эмпирической функции распределения находят середины интервалов и по ним получают эмпирическую функцию распределения аналогично точечному вариационному ряду.
Полигон и гистограмма
Для наглядности строят различные графики статистического распределения: полигон и гистограммы
Полигон частот - это ломаная, отрезки которой соединяют точки , ,..., , где - варианты, – соответствующие им частоты.
Гистограмма частот -это ступенчатая фигура, состоящая из прямоугольников, основаниями которых служат частичные интервалы длиною , а высоты равны плотности частот.
В случае непрерывного признака целесообразно строить гистограмму, для чего интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько частичных интервалов длиной и находят для каждого частичного интервала – сумму частот вариант, попавших в i-ый интервал. (Например, при измерении роста человека или веса, мы имеем дело с непрерывным признаком).
Пример:
Даны результаты изменения напряжения (в вольтах) в электросети. Составьте вариационный ряд, постройте полигон и гистограмму частот, если значения напряжения следующие: 227, 215, 230, 232, 223, 220, 228, 222, 221, 226, 226, 215, 218, 220, 216, 220, 225, 212, 217, 220.
Решение.
Составим вариационный ряд. Имеем , , .
Применим формулу Стреджесса для подсчета числа интервалов.
.
Интервальный вариационный ряд частот имеет вид:
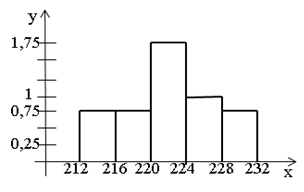
| интервалы | 212-216 | 216-220 | 220-224 | 224-228 | 228-232 |
|---|---|---|---|---|---|
| частоты | 3 | 3 | 7 | 4 | 3 |
| Относительные частоты (плотность частот) | 0,75 | 0,75 | 1,75 | 1 | 0,75 |
Построим гистограмму относительных частот
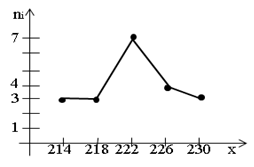
Построим полигон частот, найдя предварительно середины интервалов:
| Середины интервалов | 214 | 218 | 222 | 226 | 230 |
|---|---|---|---|---|---|
| частоты | 3 | 3 | 7 | 4 | 3 |
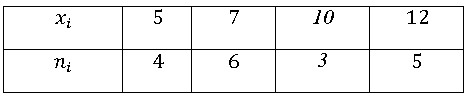
Пример точечного вариационного ряда может быть представлен таблицей:


Полигон частот - это ...
График эмпирической функции распределения ...